Các công nghệ Web đang phát triển lên một tầm cao mới giúp người dùng có những trải nghiệm tưởng chừng chỉ ở trong phim viễn tưởng của Hollywood. Để các Web thực thi được nhiệm vụ thông minh của mình, các công nghệ cốt lõi phải kể đến Web ngữ nghĩa, trí tuệ nhân tạo và chuỗi khối. Nội dung bài viết sẽ trình bày về Web ngữ nghĩa (Sementic Web), nền tảng cơ bản của một Web hiện đại ngày nay.
Trong bài phát biểu về tương lại của World Wide Web năm 1999 và được tìm thấy trong bài báo “The Semantic Web” của Berner-Lee và cộng sự năm 2001 trên tạp chí Scientific American, Tim Berners-Lee nói rằng “Web ngữ nghĩa là một phần mở rộng của trang Web hiện tại trong đó thông tin được đưa ra mang ý nghĩa được xác định rõ ràng,.., cho phép máy tính và con người hợp tác làm việc tốt hơn”. Những người thiết kế và phát triển Web ngữ nghĩa dựa trên “Semantic web tower” nổi tiếng, được Berners-Lee vẽ trên bảng trắng.
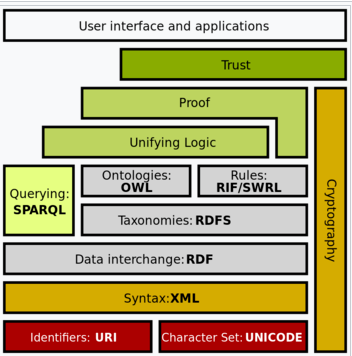 |
Hình 1. Ngăn xếp Web ngữ nghĩa
Trong ngăn xếp Web ngữ nghĩa, các công nghệ được chỉ định theo tiêu chuẩn W3C, bao gồm:
– Khung mô tả tài nguyên (RDF)
– Lược đồ RDF (RDFS)
– Hệ thống tổ chức kiến thức đơn giản (SKOS)
– SPARQL, ngôn ngữ truy vấn RDF
– Notation3 (N3), được thiết kế dành cho người dễ đọc
– N-Triples, một định dạng để lưu trữ và truyền dữ liệu
– Turtle (Terse RDF Triple Language)
– Ngôn ngữ bản thể web (OWL), một họ ngôn ngữ biểu diễn tri thức
– Định dạng trao đổi quy tắc (RIF), một khung phương ngữ ngôn ngữ quy tắc web hỗ trợ trao đổi quy tắc trên mạng
Hiện trạng tiêu chuẩn hoá:
Các tiêu chuẩn được thiết lập tốt gồm có: RDF, RDFS, Định dạng trao đổi quy tắc (RIF), SPARQL, Unicode, Định danh tài nguyên thống nhất, Ngôn ngữ bản thể web (OWL), XML.
Các tiêu chuẩn chưa thực hiện đầy đủ: Hợp nhất các lớp Logic và Proof, Ngôn ngữ quy tắc web ngữ nghĩa (SWRL).
Web ngữ nghĩa được phát triển trên World Wide Web hiện có với mong muốn trở thành nơi cung cấp các chương trình phần mềm với siêu dữ liệu có thể hiểu được bằng máy về thông tin và dữ liệu được xuất bản. Khi xây dựng web ngữ nghĩa, các bộ dữ liệu sẽ được thêm các cách mô tả thêm vào nội dung và dữ liệu hiện có trên web để giúp máy tính có thể đưa ra những diễn giải có ý nghĩa tương tự như cách con người xử lý thông tin để đạt được mục tiêu của mình.
Tim Berners-Lee tham vọng, web ngữ nghĩa cho phép máy tính thay mặt con người để xử lý thông tin nhanh hơn và hiệu quả hơn. Ông giải thích thêm rằng, trong ngữ cảnh của web ngữ nghĩa, từ “ngữ nghĩa” biểu thị cho khả năng xử lý của máy tính hoặc những gì máy có thể thực hiện với dữ liệu. Trong khi đó “web” truyền tải ý tưởng về một không gian có thể điều hướng được của các đối tượng được kết nối với nhau bằng các ánh xạ từ URI tới tài nguyên.
Để Web ngữ nghĩa hoạt động, máy tính phải có quyền truy cập vào các bộ sưu tập thông tin có cấu trúc và bộ quy tắc suy luận mà chúng có thể sử dụng để tiến hành suy luận tự động.
Các dữ liệu mở được liên kết (LOD) là dữ liệu có cấu trúc được mô hình hóa dưới dạng các biểu đồ và được xuất bản theo cách cho phép liên kết giữa các máy chủ, Điều này đã được Tim Berners-Lee chính thức hòa vào năm 2006 dưới dạng bốn quy tắc của dữ liệu được liên kết:
– Sử dụng URI làm tên cho mọi thứ
– Sử dụng URI HTTP để mọi người có thể tra cứu những tên đó
– Khi ai đó tra cứu URI, hãy cung cấp thông tin hữu ích bằng cách sử dụng các tiêu chuẩn (RDF, SPARQL)
– Bao gồm các liên kết đến các URI khác để họ có thể khám phá được nhiều điều hơn
LOD cho phép cả người và máy truy cập dữ liệu trên các máy chủ khác nhau và diễn giải ngữ nghĩa của nó dễ dàng hơn. Kết quả là, web ngữ nghĩa chuyển từ một không gian bao gồm các tài liệu được liên kết sang một không gian bao gồm các thông tin được liên kết. Ngược lại, điều này cho phép tạo ra một mạng lưới kết nối đa dạng và có ý nghĩa mà máy có thể xử lý được.
Dữ liệu liên kết mở bao gồm:
– Dữ liệu thực tế về các thực thể và khái niệm cụ thể (ví dụ: varna, lý thuyết nóng lên toàn cầu,…)
– Ontology: xác định lược đồ ngữ nghĩa
– Các lớp đối tượng (ví dụ: người, tổ chức, địa điểm, tài liệu,…)
– Các loại quan hệ (ví dụ: cha mẹ, nhà sản xuất,…)
– Các thuộc tính (ví dụ: dân số của một khu vực địa lý,…)
Ngày nay, có hàng nghìn bộ dữ liệu được xuất bản dưới dạng LOD trên các lĩnh vực khác nhau như bách khoa toàn thư, dữ liệu địa lý, dữ liệu chính phủ, cơ sở dữ liệu, bài báo khoa học,… Chỉ riêng trong khoa học đời sống, đã có hơn 100 cơ sở dữ liệu khoa học được xuất bản dưới dạng LOD.
Do có sự liên kết, các bộ dữ liệu này tạo thành một mạng dữ liệu không lồ hoặc một biểu đồ tri thức, kết nối một lượng lớn mô tả về các thực thể và khái niệm.
Siêu dữ liệu ngữ nghĩa: gắn thẻ trang web hiện có.
Siêu dữ liệu ngữ nghĩa là cá thẻ ngữ nghĩa được thêm vào các trang web thông thường đề mô tả rõ hơn ý nghĩa có chúng. Siêu dữ liệu như vậy giúp việc tìm kiếm các trang web dựa trên tiêu chí ngữ nghĩa trở nên dễ dàng hơn nhiều. Nó giải quyết mọi sự mơ hồ tiềm ẩn và đảm bảo rằng khi chúng ta tìm kiếm Paris (thủ đô của Pháp), chúng ta không nhận được các trang về Paris Hilton.
Nếu chúng ta muốn có mối quan hệ được xác định rõ ràng giữa chủ đề của trang web và trang tài liệu tương ứng, cách tốt nhất là sử dụng một trong các sơ đồ siêu dữ liệu có cấu trúc. Hiện nay, chương trình phổ biến nhất là Schema.org, được thành lập bởi Google, Yahoo, Mircrosoft và Yandex. Theo một nghiên cứu của Đại học Mannheim năm 2015, 30% trang web chứa siêu dữ liệu ngữ nghĩa.
Web ngữ nghĩa cung cấp một khuôn khổ chung cho phép dữ liệu được chia sẻ và tái sử dụng trên các ranh giới ứng dụng, doanh nghiệp và cộng đồng. Đây là nỗ lực hợp tác do W3C dẫn đầu với sự tham gia của nhiều nhà nghiên cứu và đối tác công nghiệp.
Khoa CNTT – VNUA